Abstract
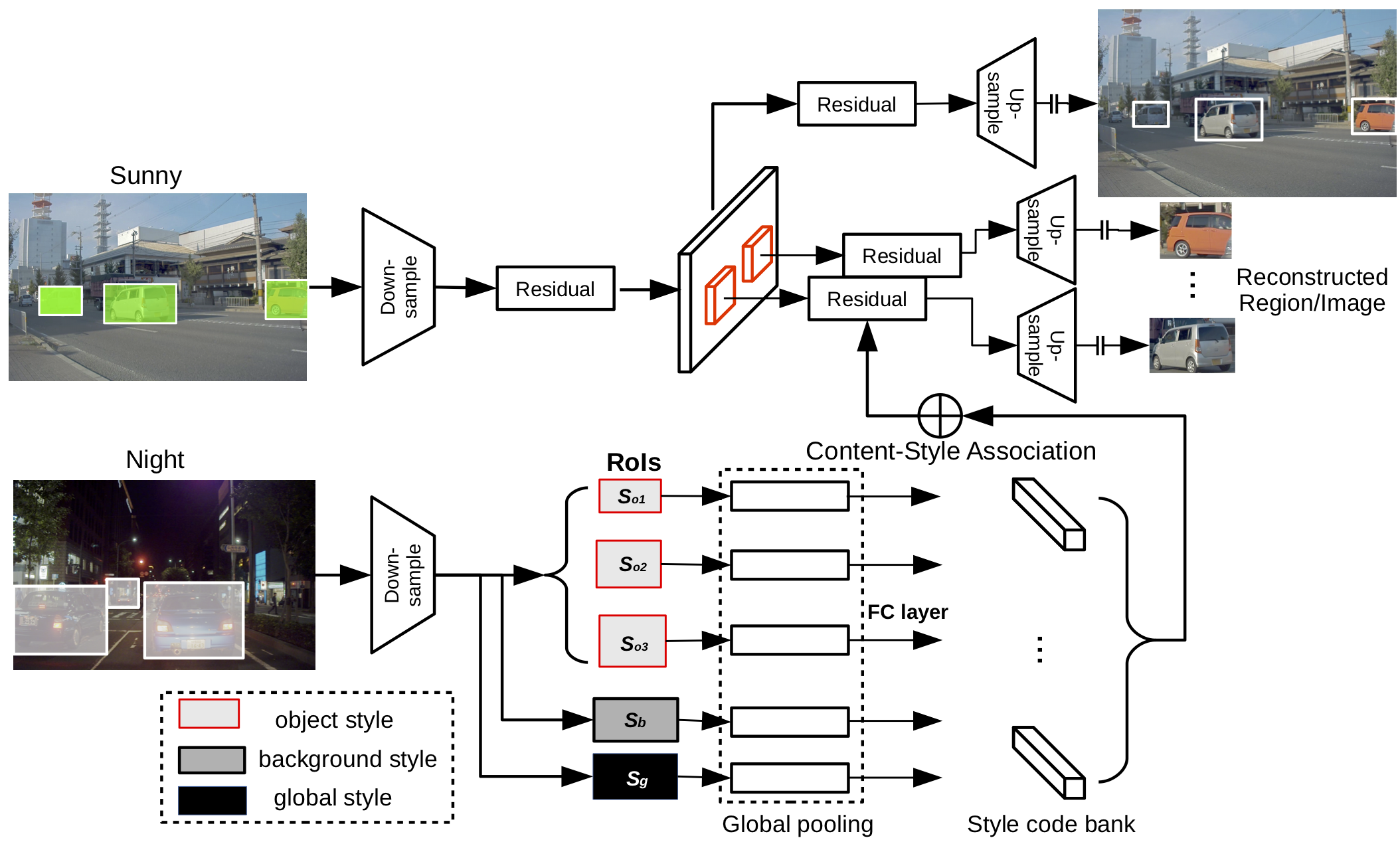
Recent advances in Unpaired Image-to-image Translation like MUNIT and DRIT mainly focus on disentangling content and style/attribute from a given image first, then directly adopting the global style to guide the model to synthesize new domain images. However, this kind of approaches severely incurs contradiction if the target domain images are content-rich with multiple discrepant objects. In this paper, we present a simple yet effective instance-aware image-to-image translation approach (INIT), which employs the fine-grained local (instance) and global styles to the target image spatially. The proposed INIT exhibits three import advantages: (1) the instance-level objective loss can help learn a more accurate reconstruction and incorporate diverse attributes of objects; (2) the styles used for target domain of local/global areas are from corresponding spatial regions in source domain, which intuitively is a more reasonable mapping; (3) the joint training process can benefit both fine and coarse granularity and incorporates instance information to improve the quality of global translation. We also collect a large-scale benchmark for the new instance-level translation task. We observe that our synthetic images can even benefit real-world vision tasks like generic object detection.
Paper
Zhiqiang Shen, Mingyang Huang, Jianping Shi, Xiangyang Xue, Thomas Huang.
Towards Instance-level Image-to-Image Translation (CVPR2019)
[paper][poster][bibtex]
Dadaset
This dataset is restricted to non-commercial research and educational purposes. (Images are hosted on Google Drive.)[Batch1 (img size: 1208x1920)]: [Sunny] (53.5G) | [Night] (23.9G) | [Cloudy] (63.7G) | [Rainy] (9.3G)
[Batch2 (img size: 3000x4000)]: [Sunny] (106.9G) | [Night] (83.8G) | [Cloudy] (97.5G) | [Rainy] (9.2G)
[Annotations]: [Batch1] | [Batch2]
[Annotation Format]: [Format]
Please cite our paper if you use this dataset or find this help your research:
@inproceedings{shen2019towards,
-
title = {Towards Instance-level Image-to-Image Translation},
author = {Shen, Zhiqiang and Huang, Mingyang and Shi, Jianping and Xue, Xiangyang and Huang, Thomas},
booktitle = {CVPR},
year = {2019}
Benchmark Visualization

Related Work
[1] Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. Multimodal unsupervised image-to-image translation. In ECCV, 2018.[2] Hsin-Ying Lee, Hung-Yu Tseng, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. Diverse image-to-image translation via disentangled representations. In ECCV, 2018.
[3] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV, 2017.
[4] Jun-Yan Zhu, Richard Zhang, Deepak Pathak, Trevor Darrell, Alexei A Efros, Oliver Wang, and Eli Shechtman. Toward multimodal image-to-image translation. In NIPS, 2017.
[5] Ming-Yu Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. In NIPS, 2017.
Comments, questions to Zhiqiang Shen
![[poster]](./cvpr19_poster.png){kind=link}