Abstract
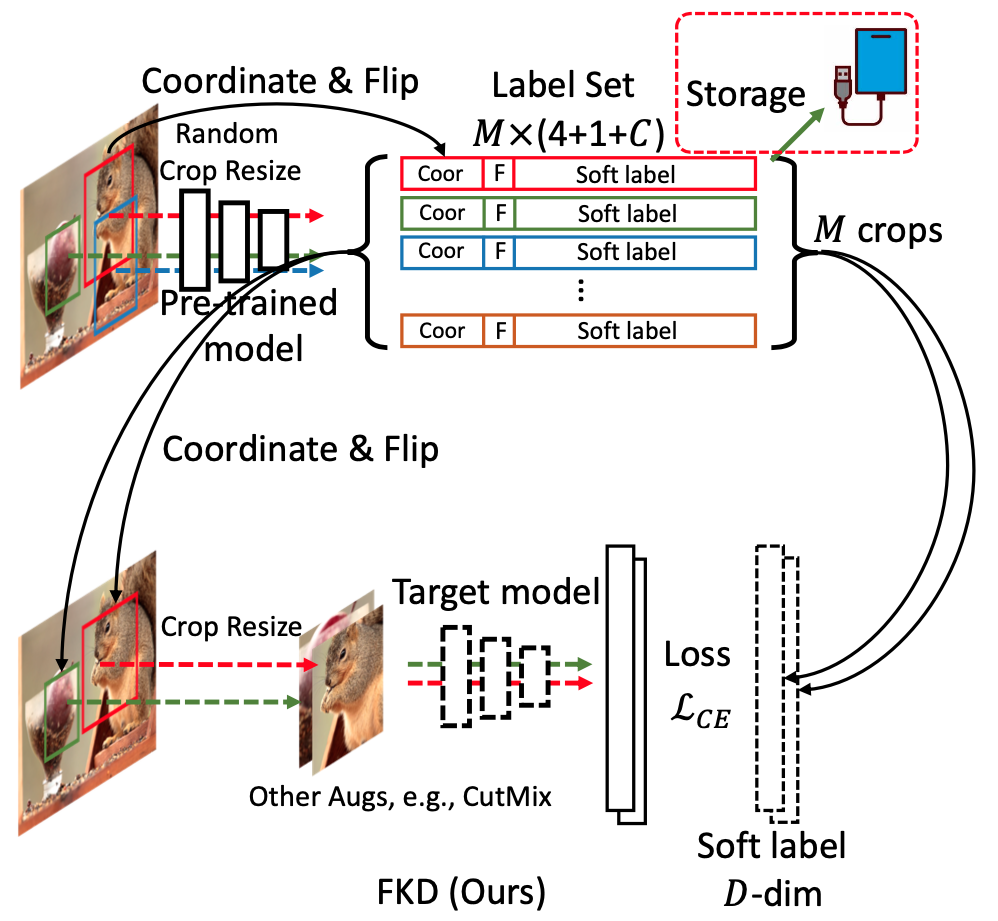
Knowledge Distillation (KD) has been recognized as a useful tool in many visual tasks, such as the supervised classification and self-supervised representation learning, while the main drawback of a vanilla KD framework lies in its mechanism that most of the computational overhead is consumed on forwarding through the giant teacher networks, which makes the whole learning procedure in a low-efficient and costly manner. Recent solution ReLabel proposes to generate a label map for the global image. During training, it obtains the cropped region-level label by RoI align on the pre-generated complete label map, which can obtain the supervision efficiently without forwarding the teachers multiple times. However, as the teachers used for KD are from the regular multi-crop training, this strategy exists several mismatches between the global label-map and region-level label, which leads to performance decline. In this paper, we propose a Fast Knowledge Distillation (FKD) framework that simulates the distillation training phase and generates soft labels following the multi-crop KD procedure, meanwhile enjoying the faster training speed than ReLabel as we have no post-processes like RoI align and softmax operations. Our FKD is even more efficient than the conventional classification framework when employing multi-crop in the same image for data loading. We achieve 80.1% using ResNet-50 on ImageNet-1K, outperforming ReLabel by 1.2% while being faster. We also demonstrate the efficiency advantage of FKD on the self-supervised learning task.
Paper
 |
Z. Shen and E. Xing.
A Fast Knowledge Distillation Framework for Visual Recognition.
ECCV 2022.
|
1. Supervised Learning on ImageNet-1K [Github]
Soft Labels from EfficientNet-L2-ns-475 pre-trained model:
Fast MEAL V2 [Github]:
Soft Labels from SENet154 + ResNet152 v1s ensemble (same as MEAL V2 paper):
Full label (uncompressed) is available upon request as its large storage. Please email to zhiqiangshen0214 AT gmail.com for it.
2. Self-Supervised Learning on ImageNet-1K [Github]
Soft Labels from MoCo V2-800ep and SwAV/RN50-w4 pre-trained model:
Please cite our paper if you use our code and soft labels, or find this help your research:
@article{shen2021afast,
title = {A Fast Knowledge Distillation Framework for Visual Recognition},
author = {Shen, Zhiqiang and Xing, Eric},
journal = {arXiv preprint arXiv:2112.01528},
year = {2021}
}