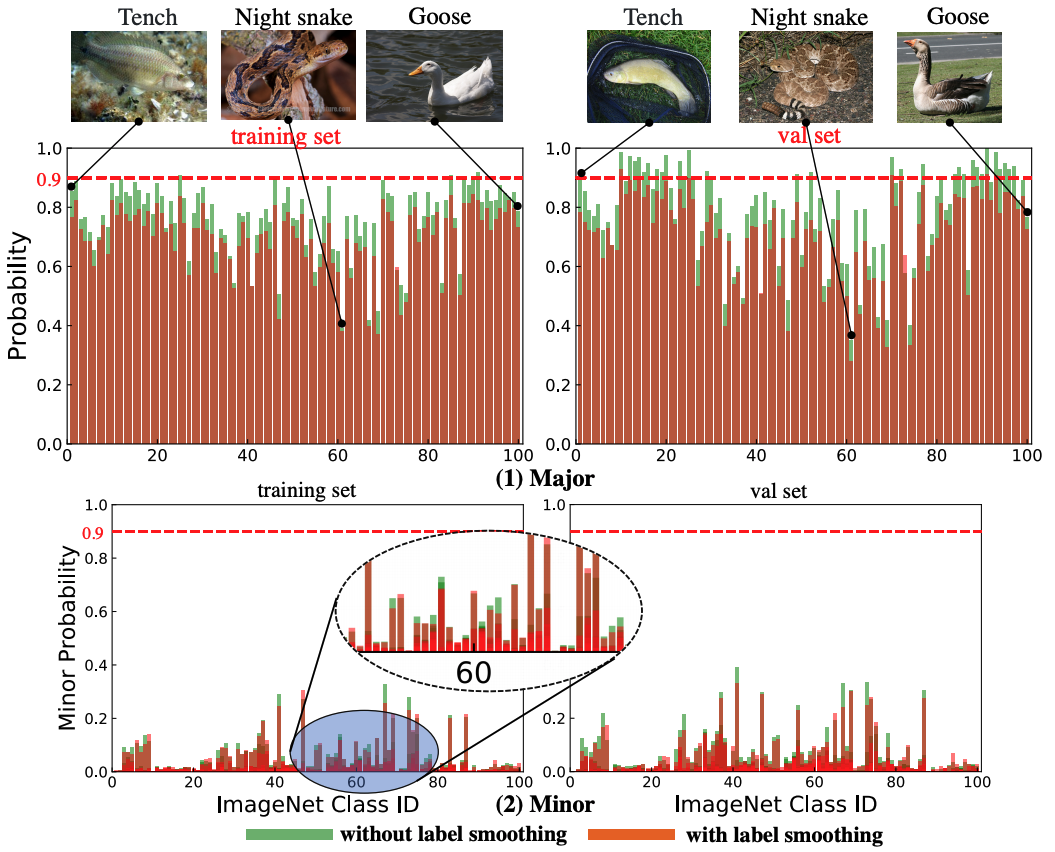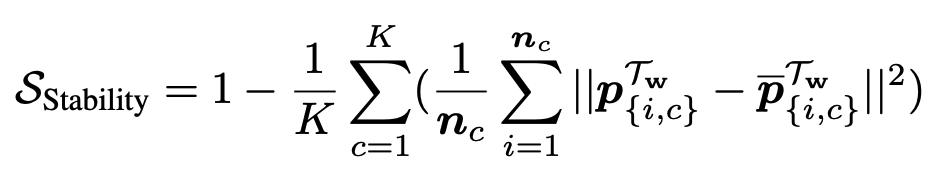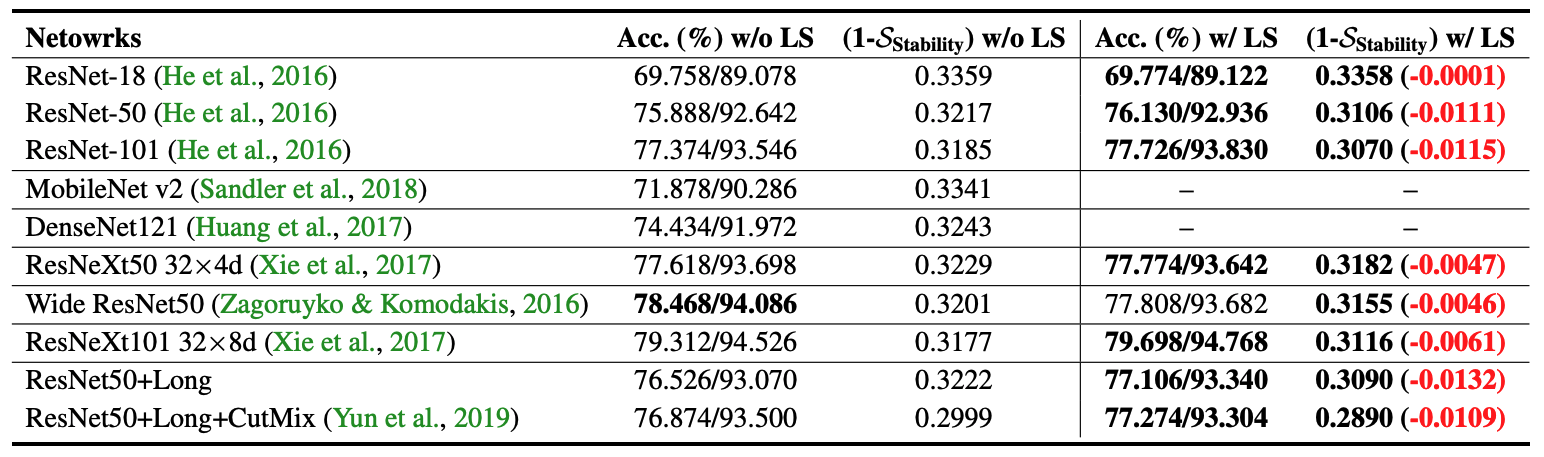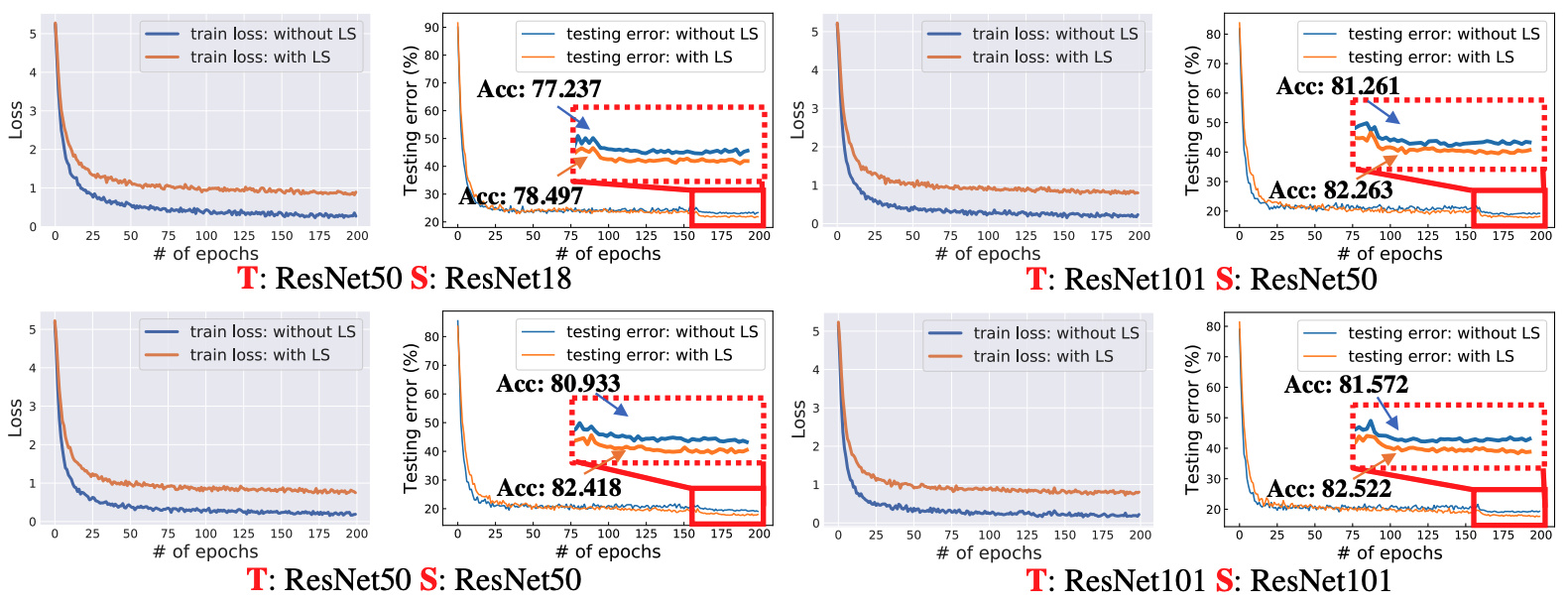
| Zhiqiang Shen1 Zechun Liu12 Dejia Xu3 Zitian Chen4 Kwang-Ting Cheng2 Marios Savvides1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
Z. Shen, Z. Liu, D. Xu, Z. Chen, K. Cheng, M. Savvides. Is Label Smoothing Truly Incompatible with Knowledge Distillation: An Empirical Study. ICLR, 2021. |
|
|